原文:http://servers.pconline.com.cn/721/7215376.html
编者按:11月16日,阿里“双十一”技术分享会上,阿里巴巴技术保障部研究员林昊详细解析了“异地多活”技术。相较于目前主流的“两地三中心”,该技术实现了质的飞跃。笔者对此的理解是,“提供‘丝般柔顺’的用户体验”,即用户在天猫、淘宝等阿里平台上的任何操作都流畅自如。而更为深入的技术剖析,请参阅以下演讲实录。
在去年“双十一”之后,阿里巴巴就对外宣传了去年交易的“异地双活”,而今年则变成了“异地多活”,意味着从双走向了更多。
对于阿里的交易以及支付来讲,我们做异地多活最重要的目的除了灾备之外,更重要的点是追求持续可用,整个支付交易的体量对于用户来讲是持续可用。
我们可以看一下业界比较主流的灾备是怎么做的,以及阿里在这方面整个的演进。业界最重要的很多人都知道,最主流的灾备技术是两地三中心,数据中心A和数据中心B在同城作为生产级的机房,当用户访问的时候随机访问到数据中心A或B。之所以随便访问,因为A和B会同步做数据复制,所以两边的数据是完全一样的。但是因为是同步复制的,所以只能在同城去做两个数据中心,否则太远的话同步复制的延时会太长。在两地三中心的概念里,一定会要求这两个生产级的数据中心是必须在同一个城市,或者在距离很近的另外一个城市也可以,但是距离是有要求的。
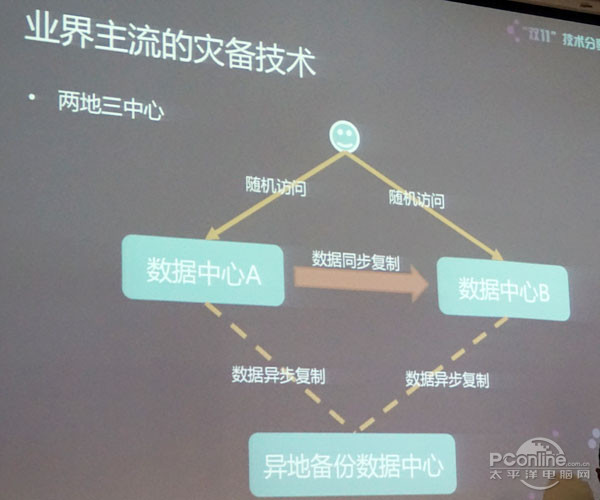
异地备份数据中心通过异步复制去走,但是两地三中心很明显的是异地备份的数据中心是不起用的,正常情况下不对外服务,所以用户不会访问到异地的点。原因是因为数据从生产级数据中心到异地的节点是异步去复制,所以整个有延时。这是整个业界目前用的比较多的业界。
两地三中心对于阿里来讲看到的问题,最重要的问题:
1、这个模式不一定Work。大家可能都看到某些新闻里讲过,比如说某些地方用了两地三中心之后,当一地的数据中心出问题的时候,是不敢流量切往异地的备份数据中心,原因是异地的备份数据中心是冷的,平时是没有用户流量进去的。如果要把流量切到那边起来之后,其实没有人有多强的信心能够保障起用以后是可以正常服务的,毕竟平时都是冷的。因为是冷的,就意味着整个起用的过程需要时间,不可能说起用就起用,一定会有时间周期。这是两地三中心的最大问题,看起来模式是很安全的,也是可用的,但是事实上不一定是这样。
2、异地备份中心因为不对外提供服务,所以整个资源会处于浪费状态,成本比较高及
3、对于阿里的规模来讲有一个很大的问题,在两地三中心中,数据一定是单点去写。其实数据只在一个地方去写,这个时候如果整个压力比较高,比如像“双十一”的场景中压力非常高的情况下,就意味着在两地三中心的情况下所有的数据还是写上的单个点,对于存储成本压力会不断增加。比如去年8万、今年14万意味着每年压力都在增加,这时候数据库整个伸缩和外层业务的伸缩都面临着更大挑战。
对于我们来讲这三个问题是比较明显的。
阿里在整个高可用上也经历过了一段时间,主要是做了三个步骤。第一个是做了同城的双活,第二个做了异地只读及冷备,第三个是做了异地多活,经历了三代体系的演进才走到了今天。

异地多活前我简单讲一下,在异地多活之前,最重要是同城的“双活”,双活上打了一个引号。原因在于同城双活的情况下,其实整个模式是应用层是双活的,两边的业务都有,用户访问过去都会处理请求。但是存储层都是主备的,存储主在A机房,备在B机房,不会同时用,可以说是伪双活,不是真正意义上的双活。阿里做同城双活做了挺长一段时间才真正做成功,因为双活其实也是一样的,如果真正做到就意味着同城任何一个机房出问题都可以切换到另外一个机房,如果没有经过很多次真正切换的话,是没有人敢说是一定能成功的。所以阿里在那一年也是花了时间演练了非常多次,才真正能做到。
在完成同城双活的改造之后开始尝试异地,同城毕竟还是有很多因素的风险,所以去尝试能不能走到异地远的城市。最早尝试的是只读业务和冷备,把阿里的某些业务部署到另外一个城市去,开始只是冷备用,冷备后来完全没有办法接受,因为阿里的规模一年比一年大,冷备的成本越来越高,这个钱不值得付出。另外是冷备不Work,出状况下不敢迁到异地去。
后来在这上面做了一点改进,所以决定把只读业务在异地起用,比如说像搜索等等算只读。但是发现对于阿里业务来讲,只读业务很难抽象,因为只能服务只读业务,如果有写就不能做。如果写的话,就意味着写到另外一个城市,这个延时接受不了,后来只读也觉得没有太大意义。
当阿里完成同城双活以及异地只读、冷备尝试以后,阿里的阶段也是两地三中心,跟两地三中心是一样的。可以认为是两地三中心稍微的升级版本,因为只读业务有部分的开放,有一部分的进步,但不是最理想的状态。
阿里决定开始做异地多活,对于我们来讲,我们要去做到异地多活,要的目标是:
1、需要多个跨地域的数据中心。异地多活是跨地域的,而且距离一定要做到1000公里以上的范围,其实在中国范围内全国城市都可以去布了。
2、每个数据中心都要承担用户的读写流量。如果只是备或只读业务来讲,作用不是很大。
3、多点写。因为每个数据中心去承担用户读写流量的话,如果读或写集中到全国一个点的话,整个延迟是没有办法承受的。
4、任意一个数据中心出问题的时候,其他中心都可以分钟级去接管用户的流量。
这个是阿里在做异地多活项目的时候,希望在这四点上都能够做到,然后也只有这样的情况下才认为是一个异地多活的业务。
异地多活对于我们来讲,其实很多人都可以看到异地多活最大的挑战是什么?
1、距离。看起来距离没有什么,比如说1000公里以上也就是30毫秒的网络延迟,来回一次是30毫秒左右。30毫秒对于用户来讲,如果只是给你增加30毫秒,用户其实没有感受。但是当你打开一个淘宝页面的时候,事实上当你在商品页面看到一个商品点立刻购买的时候,页面的背后大概有100多次以上的后端交互,如果100多次全部跨地域完成的话,就意味着页面的响应时间将增加3秒。如果增加3秒,用户绝对会有明显感受。因为对于阿里来讲,很多页面就出不来了,3秒已经超时了。对于我们来讲,这第一点是直接带来用户体验的不可用。
成本,当系统响应时间增高的时候,意味着每年“双十一”增加的QPS将付出更大的成本,因为吞吐量在下降,这个时候的成本也是很难接受的。距离带来的延时问题是最大的问题。
2、既然要解决掉距离的问题,多点写是解决距离的问题,如果没有延时问题可以不多点写。只要开始多点写了就会带来第二个最复杂的问题,其实我们认为第一点延时问题一定程度也许可以强制接受,也就是能够打开,打不开就有问题了。如果一旦出现多点写带来的数据正确性问题,这对我们来讲是最致命的。多点写,比如说出现这一次访问在A数据中心写的数据,然后再访问的时候到B数据中心又写了一条数据,两条数据如果合不到一起的话。对于大家最直观的感受是有可能买了一个东西付了钱,然后看到可能是没付钱。或者干脆买了一个东西,压根就没有看到购买。对于阿里来讲,这是最大的一个问题。
对于我们来讲,在多点写的情况下最大的挑战是怎么保证用户写入的数据一定是在正确的地方,另外看到的一定是一致的,这是整个异地多活中最大的挑战。
针对这两个个问题,对于延时的问题来讲,其实延长时的问题意味着最好的解决方案是什么呢?如果这一次访问页面的整个操作全部在当前机房内完成的,自然就不存在延时问题,因为没有跨出去。
针对第二个问题,异地。在全国部署的时候,意味着是不是要把整个业务全部全国部署,因为这有成本因素。大家知道阿里的业务非常庞杂,其实没有必要把所有的业务都在全国部署,因为不是所有的业务都有足够的量。
因为不是整个业务全国部署,所以决定起另外一个名字叫单元化。意味着我是把业务划成了各种各样的单元,比如有交易的单元,这个单元是完成交易业务,所以在内部代号是单元化项目。
为了解决延时问题,能在一个机房内完成就不存在延时问题。另外一个核心思想是单元封闭,需要让单元内的应用访问和数据的读写操作全部处于封闭状态,这就是最完美的状况。如果能做到这样,其实在全国任意城市部署都不会有问题。
开始多点写以后,怎么去保障整个数据写入的正确性以及一致性。阿里确实做了非常多的东西,因为一个用户访问阿里的时候,其实阿里的背后是庞大的分布式系统,你访问了一层可能只访问了一个系统,事实上背后牵涉进来几十个系统。咱们把整你在访问每一层的时候路由都是正确的,比如这个用户访问数据中心A,但是由于某个原因访问到数据中心B,怎么在保证后面访问不同系统的时候准确跳转到正确的地方去,因为每个数据中心的数据不太一样。
为了保证一个用户真正写数据的时候不要写错,写入数据库之前都会做保护动作,确保用户写的数据没有写错一个地方。如果写错一个地方,可能就无法恢复了,所以在那个地方有最后的一层保护。同时有实时数据校验系统检查是否符合我们的期望。
对于异地多活来讲,还有数据一致性中很大的挑战会出现在流量切换的动作中,比如说AB两个数据中心,A开始是承担20%的流量,8承担80%的流量。当把流量从一个地方切到另外一个地方的时间,有可能出现切换过程中你还在A数据中心写,但其实写完之后到B了,有可能看到出现的数据是不一致的。怎么保证在整个流量切换过程中数据是绝对一致的,我们也做了很多的东西。
在异地整个数据中心还有另外一个非常重要的核心技术产品,就是我们需要一个数据同步的东西。因为大家知道阿里现在除了OB以外,很重要的一块是MySQL,MySQL自己的主备是没有办法满足要求,在异地做到延时是没有办法满足的,我们决定做了自研的数据同步产品。在2015年“双十一”中,所有数据同步控制在1秒以内,1秒以内是可以接受的。
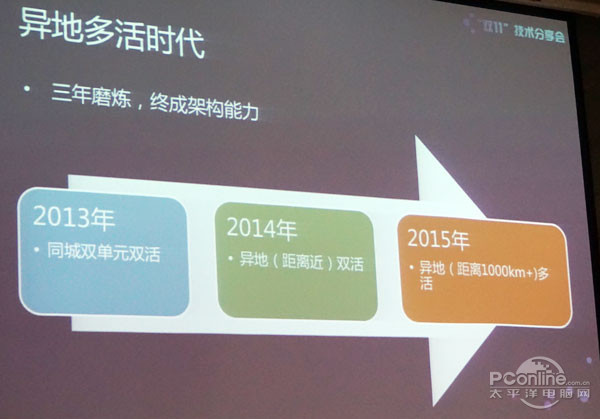
阿里为了做到整个异地多活,其实自己也折腾了很多年。这个项目在阿里内部总共花了三年的时间,自己在最近的一封总结邮件中也写到,经历了三年的磨炼,我们终于把异地多活变成了阿里电商架构级的能力,意味着在整个架构中具备异地多活的能力,在以前也许不一定具备。
我们为了整个过程中是比较平滑的,因为不能对业务产生太大影响,所以分了三年的时间去完成。在2013年首先采用的是在同城起用了两个单元双活,真正意义的双活,因为那两个单元都是写自己的数据库的,两个单元都是双写。
之所以在2013年选择同一个城市,是因为我们担心单元化改造没有完成的情况下如果走向异地,可能会因为延时问题导致页面打不开,那个问题是非常严重的,所以决定先在同城做。同城的话,及时没有改造好,跨出去了也没有关系,因为还在同城,延时是可控的。
在2014年觉得可以往前更进一步,选择了距离更近的城市,其实还是有延时。如果没有做过单元化改造业务部署到异地的时候,页面会超时,有些页面打不开。但是因为单元化在背后就没有太大问题,在2014年成功在两个相距有一定距离的城市起用了异地双活,在去年“双十一”中两个城市分别承担了50%的用户流量,有些用户会访问一个城市,有些用户访问另外一个城市,当下单的时候会下在同一个城市里面。
在今年单元化可以宣告能力基本成熟的阶段,所以在今年开始起用了距离在1000公里以上的另外一个数据中心,然后今年数据中心是多点部署。从2015年从2个变成3个或4个以后,对于我们来讲的另外一点是因为距离增加到了1000公里以上,基本上意味着阿里整个电商以及支付是可以在全国任意一个城市去部署,并且可以部署多个,意味着以后的“双十一”整个扩充能力是会变得很容易。
对于我们来讲,当阿里整个架构能力进一步提升到了异地多活时代以后,对于我们来讲带来了两个好处:
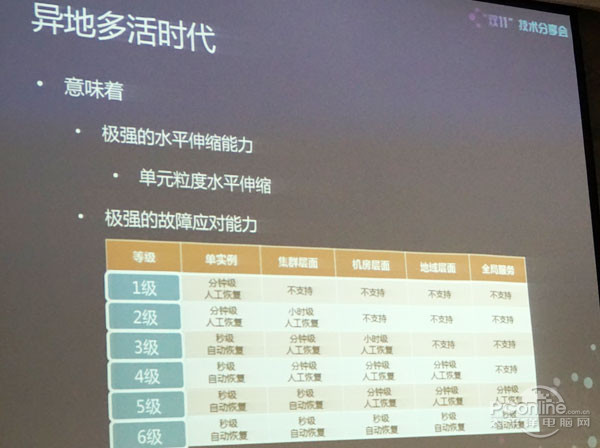
第一、有极强的水平伸缩能力。以前做“双十一”的时候,都必须去算,比如去年8万笔,今年14万笔的时候,必须要算增加的6万。还有因为每年业务模式的变化需要算每个应用加多少机器。但是在单元的情况下,一组单元就是多大的能力,然后只要按照单元扩充就结束了。假设一个单元可以做到2万笔,其实14万笔对于我们来讲是建设7个单元就结束了,整个伸缩能力会比以前强大非常多。而且每个单元都是写自己的数据库和存储层,包括cache全部写自己的,这个时候伸缩规模是可控的,不像以前不断加,数据库有可能抗不住。在抗不住的时候可能会做分布等等,但其实也是比较复杂的,现在我们改变了伸缩力度的模式。
第二、异地多活怎么去应对故障。比如在阿里内部会按照这样的等级去划分所有业务能够支持故障应对能力,比如说单实例出故障在多久能恢复,或者单机房或单城市或全局的服务,比如DNS等等,我们会按照这个对每个业务,然后就知道每个业务当出现故障时整个应对能力是怎样的。
这个是今年“双十一”的图,背后有一个淘宝的异地多活,在这张图上可以看到有4个点的流量。如果大家去翻去年的“双十一”,发现去年是2个点,然后今年变成了4个点。下面的比例是我们随时都可以变化的,所以大家不用太在意。其实淘宝的异地多活或者整个阿里的交易额支付其实经常切,比如在昨天就切了好几次流量。其实我们整个是可以不断去做的。支付宝和淘宝稍微有点不同,支付宝今年起用了两个,分别是华南和华东,分别有不同比率的流量。
在阿里做完以后,希望整个异地多活的能力能逐渐演变成业界的,比如说在阿里做了整个多活以后,其实金融行业也不再希望自己只是一个两地三中心而已,希望更加往前前进一步,对于他们来讲整个投入会更加划算。另外容灾能力会更强。阿里把自己异地多活的能力沉淀成不同的东西,比如支付宝、蚂蚁金服把自己的能力承担到金融云里,就意味着在金融云上搭建的金融系统会自然具备异地多活的能力。

阿里自己也经历了三年的磨炼,阿里云很大的价值是可以让你在更简单的情况下获取到更强大的能力。比如阿里云的产品中像前段时间开放的DTS,内部做多个数据中心之间数据同步的产品。像下面的EDAS、DRDS、ONS是内部的中间件产品,在做整个异地多活过程中所有中间件都需要改造,否则没有办法做异地多活。这些开放的产品,自然在内部具备了异地多活的能力。所以当外部用户去用的时候,当演进到这一步会比阿里巴巴简单很多,因为阿里逐渐往外开放。